Synthetic data is data created by a machine rather than a human. It has being around for quite some time in ML and AI, as it is closely tied to data augmentation techniques. Nowadays, synthetic data aims to reducen human involvement from the loop of making AI and make the process easier for them, as shown by Anthropic’s training methods and the the new Superalignment team from OpenAI.
This blog post discusses some of the topics covered Nathan Lambert’s amazing post about the current use of synthetic data in the AI, relating them to our distilabel open-source framework for AI feedback. You can read Nathan's blog post here.
Can synthetic data be the next breakthrough?
Can synthetic data provide the next breakthrough? A core assumption backing up the use of synthetic data is scale: adding more data will make a model better if the quality is high enough. We believe that it will likely need human involvement to make it work. Getting enough data to train models a hundred times bigger than today’s will require huge amounts of synthetic data. However, there’s also a counter-argument against it: synthetic data from the same distribution as the current best model will not advance the state of the art. Nevertheless, Nathan believes current GPT4 tokens are good enough to help GPT5 push boundaries. As big companies use synthetic data to move forward and scale, smaller companies rely on it because real data in the same scale is much more expensive. Synthetic data is also highly prevalent, as it can be used for well-established predictive tasks like quality rating but also for generative tasks, like creating the options for a preference dataset.
RLAIF and Anthropic’s use of synthetic data
Anthropic pioneered a method called Constitutional AI, and it is the largest confirmed usage of synthetic data so far. This concept can be summarised in two main points:
- When the model generates answers to questions, it checks the answer against the list of principles in their Constitution, curated by Anthropic’s employees to make the models helpful and harmless.
- The LLM is used to generate preference data, as we use it to classify the best completions. Then, RLHF (Reinforcement Learning from Human Feedback) proceeds as normal with the synthetic data, hence the name Reinforcement Learning from AI Feedback (RLAIF).
Synthetic instructions, preferences, critiques, and humans in the loop
Models like Alpaca and Vicuna used synthetic instruction data for the supervised fine-tuning of Llama models to reach their impressive performance at the 7-13B parameter range. The space of foundational models has become extremely dense as new models are coming out weekly.
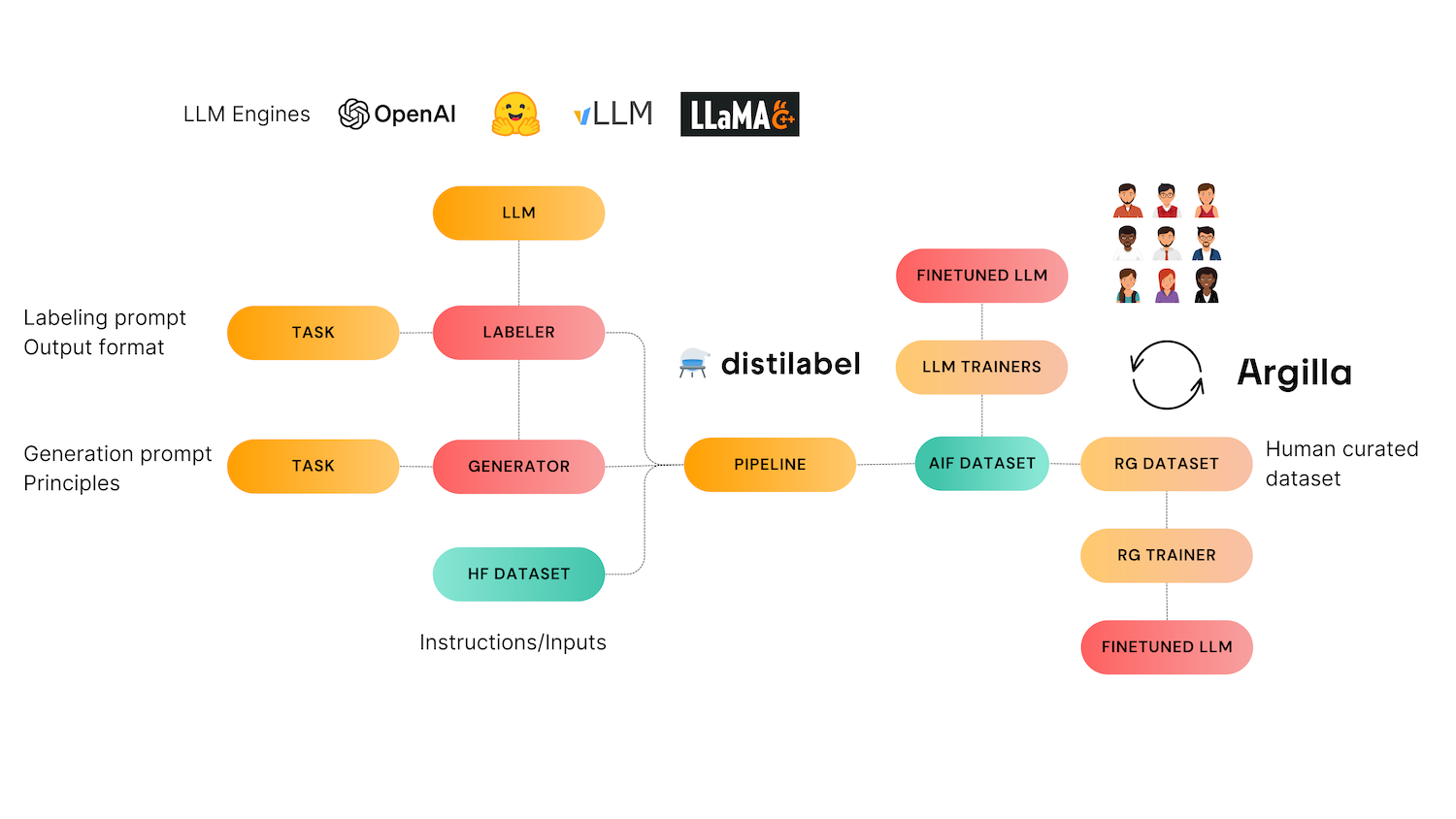
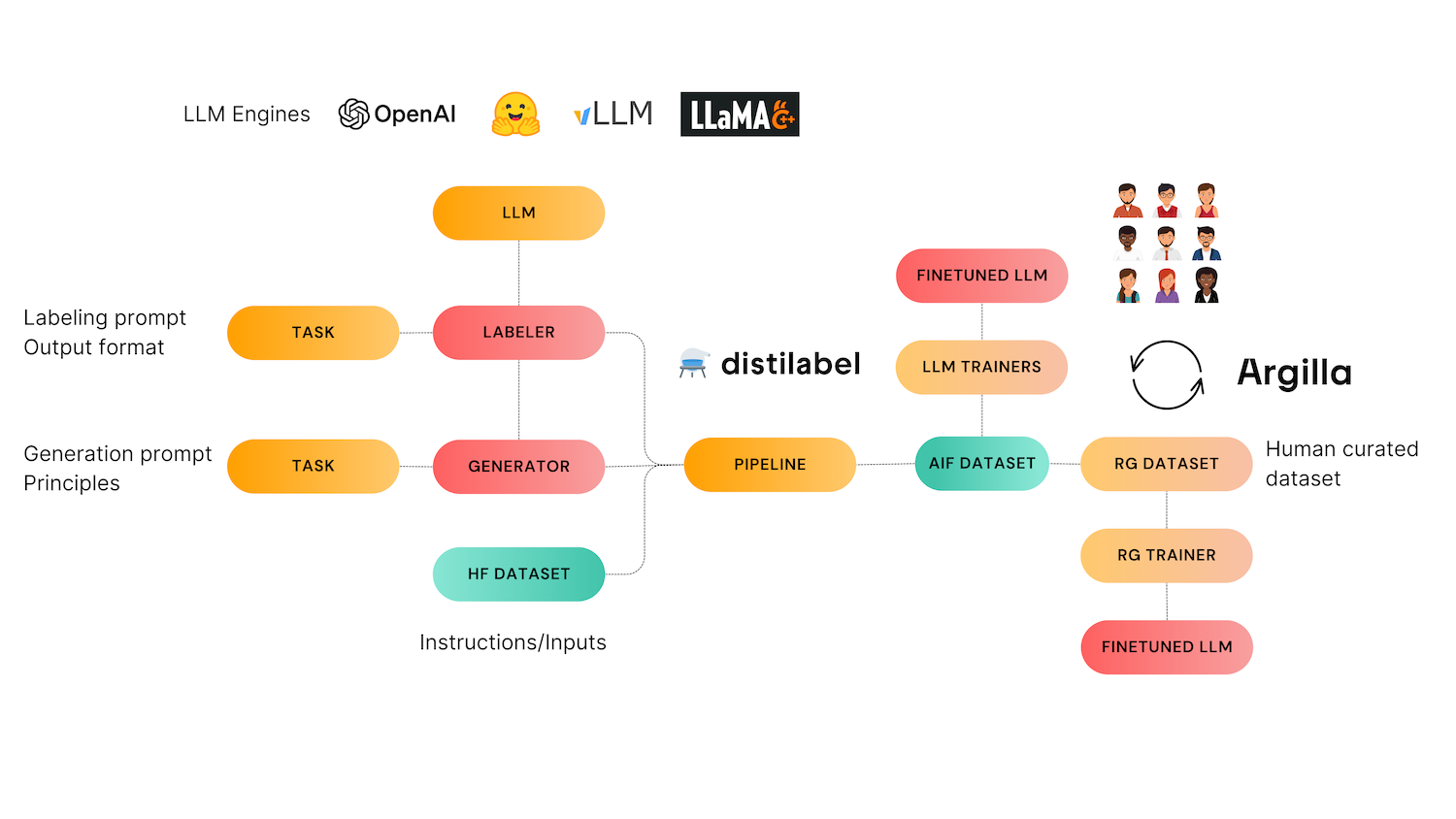
Many open instruction datasets are advanced in Self-Instruct style methods, in which one can create a set of “seed” instructions and use LLMs to generate new instructions similar to them. On the other hand, one must be careful, as prompt datasets like ShareGPT have a really low average quality and narrow distributions, which make data curation even more important (check the LIMA paper here). This is where Argilla and distilabel come to the rescue! distilabel focuses on synthetic data generation, and Argilla is helpful for data curation.
In distilabel, the Self Instruct task can be defined in a few lines of code. The pipelines gets a set of initial inputs and a description of what kind of application will be responding to this instructions. As opposed to other self-instruct methods that generate both instructions and responses, our approach generates only instructions. By splitting the instruction and response generation steps, we aim to avoid existing quality issues shown by other methods, where bad quality and non-sensical instructions lead to bad responses. In distilabel, you first generate instructions, curate them (either with manual exploration or programmatically), and then use them to generate diverse responses with the text generation or preference distilabel pipelines. These instructions can then be used with the Preference and soon the Critique task to generate AI Feedback data, which can in turn be used for LLM alignment.
The human revision approach was used to create Notus, a 7B DPO fine-tuned version of the supervised fine-tuned (SFT) version of Zephyr. Developing Notus, we discovered by using Argilla, that there was a strong mismatch between the overall score for the critique and the quality of the responses. A curated version of the dataset was generated, and the model was fine-tuned surpassing the initial model in two benchmarks.
The final frontier, in Nathan’s point of view, is to make preference or instruction data generated through AI critiques: the process of repeatedly using an LLM concerning a specific principle or question. Adding more context into the process makes the prerequisite capabilities of the model much higher for critiquing synthetic data.
How does distilabel tackle synthetic data for LLM fine-tuning?
In this image, we can see the graphic Nathan uses to highlight the different uses of synthetic data: from instruction generation, through preferences, up until critiques. Distilabel is the only OSS framework tackling all these stages at scale. There are great instruction generation approaches, both in the research literature and more practical frameworks. Our Self Instruct task is intentionally simple and aimed at those practitioners that don't have instructions/prompts to get started with preference dataset building. Preference and Critique models are our most important contribution and our major focus. You can use any instruction generation mechanism and still benefit from high performance preference models and task
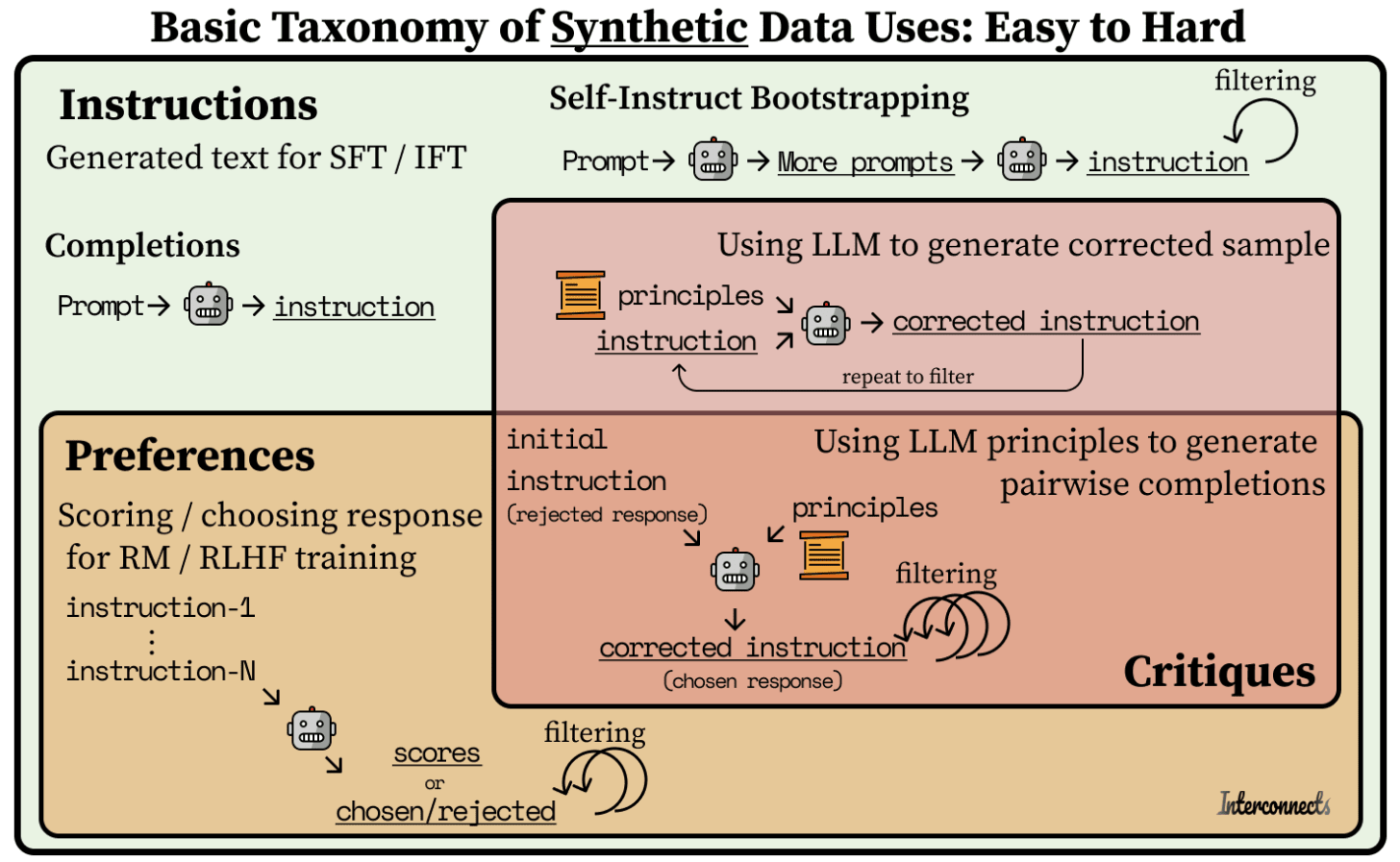
- It generates instructions using prompts as inputs.
- It can create preference datasets out of sets of instructions that can be scored or chosen later in the pipeline.
- Very soon, it will be able to combine instructions with principles (similar to Anthropic’s Constitutions) to create corrected, improved instructions.
If you are like this work and are interested in data quality, AIF, LLMs and NLP, join our Slack community and leave a star on our repos: distilabel and argilla!