Introduction
This is a series of blog posts related to alternatives to Reinforcement Learning by Human Feedback, created as a joint effort between Argilla and MantisNLP teams. Please make sure you have gone through the first, second, third, and fourth entries in the series to fully understand the context and progression of the discussion before moving on to this segment.
In the first post in this series, we explored the importance of Supervised Fine-Tuning (SFT) to optimize a pre-trained LLM for specialized tasks, and the nature of instruction-based data needed for this process.
In the second post, we described the process of Reinforcement Learning with Human Feedback (RLHF) and the reason why high-quality preference data is required.
In the third one, we focused on Direct Preference Optimization (DPO) and Chain of Hindsight (CoH), which are more straightforward as they show that the LLM can also work as the reward model using human preference data to determine the preferred responses.
In the last one, Reinforcement Learning from AI Feedback (RLAIF) was introduced to tackle the challenge of requiring human-labeled data by creating its own preference dataset.
Why Self-Play fIne-tuNing (SPIN)?
In previous discussions, we highlighted the growing interest in methods that allow LLMs to improve their performance without relying on the continuous need for new annotated data, specifically human-annotated data. To address this challenge, solutions like the already mentioned RLAIF have been developed. Next, we will introduce SPIN.
Can we empower a weak LLM to improve itself without acquiring additional human-annotated data?
This was the question that the research team addressed. And the answer was positive.
SPIN goes a step further and is independent of annotators either human or sophisticated LLMs. Inspired by AlphaGo Zero's self-play mechanism, it works by competing against its previous version without requiring any direct supervision and creating its own training data. Through successive rounds of self-play, the model gradually improves, aiming to bring its responses closer and closer to human-like ones.
This method significantly boosts model performance across various benchmarks, such as HuggingFace Open LLM Leaderboard and MT-Bench, by overcoming the constraints of SFT. However, SPIN faces a limitation: its success depends on matching the LLM's output with the target human-generated data distribution. This means there's a cap to how much an LLM can improve by fine-tuning, which is directly related to the quality of the training data.
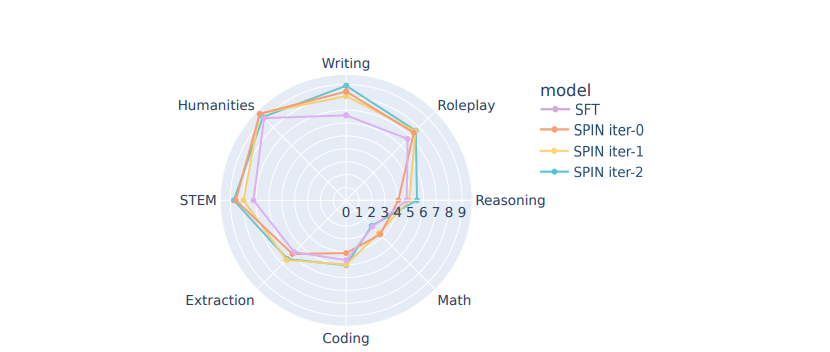
How does SPIN work?
SPIN can be understood as a two-player game, so let’s define their “rules”. For more information, you can check an available implementation on GitHub.
Players' Role
- Main player: It is the current LLM obtained by fine-tuning it to favor answers from the target dataset rather than those produced by its previous version. Its objective is to discern the responses generated by the LLM and those generated by the human.
- Opponent: It is the old LLM from the previous iteration. It aims to produce responses that closely mimic those of a human.
Rounds
The game starts with the selection of an SFT LLM and its QA training dataset. Then, the next steps are repeated and the models switch their roles at each “round”:
- Generate new synthetic answers: During the first iteration, apply this SFT model to produce alternative answers to questions from the SFT dataset. For subsequent cycles, employ the latest fine-tuned model, aiming to maximize its expected performance. To prevent significant deviations from the previous model version and ensure stability, a Kullback-Leibler (KL) regularization term is used.
- Create a training dataset: Create a new training dataset with pairs of the original (accepted) answers with the newly generated synthetic (rejected) answers.
- Fine-tune the LLM on the created training dataset: Fine-tune a new model version aimed at enhancing its response policy by distinguishing between its generated responses and human responses from the original dataset. This distinction is assessed using logistic loss, which helps prevent excessive increases in the function's absolute value.

For instance, the image above illustrates the initial model output with possible hallucinations (rejected) at iteration 0, alongside the chosen correct example (original). It also shows the enhanced model output after fine-tuning at iteration 1.
When does the game end?
With each iteration, the main player gets better at identifying human-generated responses, while the opponent improves at generating responses that mimic human responses. This "two-player game" ends when the most sophisticated version of the LLM can no longer discern between responses generated by its predecessor and those generated by humans.
As a result, the probability distribution of the generated data and the human data will converge. This means that the model-generated responses are indistinguishable from the target data, and therefore of better quality.
DPO vs SPIN
SPIN and the DPO method share similarities, yet they differ in several key aspects, making them comparable approaches:
- SPIN relies solely on the SFT dataset, making it a less costly approach. DPO requires extra preference data.
- SPIN is tailored for SFT, whereas DPO is designed for reinforcement learning fine-tuning.
- From an instance level, the chosen response needs to be better in DPO. SPIN focuses on distinguishing the target data distribution from that of a weaker LLM at a distributional level, before improving the LLM's strength.
- DPO employs a single-iteration approach, while SPIN adopts an iterative self-play strategy.
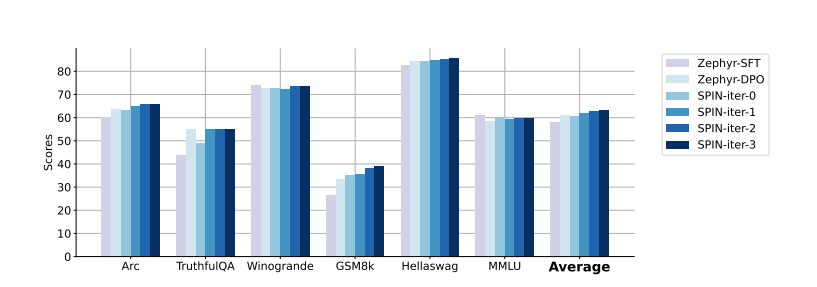
Analyzing the performance of zephyr-7b-sft-full trained with either DPO or SPIN reveals that, from the same SFT checkpoint, SPIN, with less data, matches and even surpasses DPO's average performance right from the initial iteration and, in iteration 1, outperforms DPO on the leaderboard benchmark. This demonstrates SPIN's efficiency and effectiveness in leveraging available resources.
Conclusions
SPIN is a groundbreaking approach to improving LLMs. It minimizes the dependence on new annotations and has successfully matched and even surpassed traditional preference tuning approaches, including those beyond the realm of RLHF, even being limited by the quality of the target data. This provides a strong foundation for further research to reduce the input data or complement it with other methods and demonstrates its potential to advance the field of LLM improvement.
Want to know more?
This is the fifth entry of a series of 6 blog posts dedicated to alternatives to RLHF. The first, second, third, and fourth posts of the series can be found on our website too.
Argilla and Mantis NLP teams are happy to help with any question you may have about preparation steps for training a LLM using Supervised fine-tuning, Reinforcement Learning, or Direct Preference Optimization.
All the data curation steps are currently supported by Argilla’s Data Platform for LLM, and from Mantis NLP we offer end-to-end support for the whole process.