
A few shot NER cook-off with concise-concepts!
May 5, 2022
Hola! I'm David and I love cooking 👨🏽🍳 and coding 👨🏽💻.
This post will introduce few-shot-learning and Named Entity Recognition (NER) without having to rely on fancy deep learning models, which are often only available for English. I will show you how to recognize ingredients from recipes without training a model to do so. Also, I will use Rubrix for analyzing the results and to build a manually curated training set with a human-in-the-loop approach. Here's a video showing the Rubrix dataset I created for this blog post:
During my time at Pandora Intelligence, I lobied for creating cool open-source stuff. So recently, I wrote a spaCy package, called concise-concepts, which can be used for few-shot-NER.
Do you want to stay updated on me or Pandora Intelligence. Follow us on Github!
Concise Concepts
Generally, pre-trained NER models are trained to recognize a fixed set 17 general entity labels like Person (PER), Location (LOC), and Organization (ORG). For our use case, we would like to identify ingredients like 'fruits', 'vegetables', 'meat', 'dairy', 'herbs' and 'carbs'.
Ideally, we would like to train a custom model, which means that we would need enough high quality labelled training data with the new set of labels. Rubrix comes in handy for annotating, improving, and managing this data. But, oftentimes, starting data annotation from scratch is costly or not feasible, that's why having a way to "pre-annotate", asess training-free methods, or even skip the data annotation process altogether can be highly beneficial. Within concise-concepts, few-shot NER is done by relying on the reasoning behind word2vec.
Models like word2vec have been designed based on a simple idea: words that are used in similar context have similar meaning. During training, words are mapped to a vector space, where similar words should end up in a similar region within that vector space. This allows us to do two things:
- Retrieve the n most similar words. Based on a few examples per label, we can now create a list of other words that likely belong to that label. Using this list, we can then label new data by finding exact word matches.
- Compare word vectors for similarity. After having found these exact word matches, we can compare their vectors against the vectors of the entire group. This comparison can determine how represenative the word is for the group, which can be used to provide a confidence score for the recognized entity.
Want to know more about concise-concepts? Feel free to watch this YouTube video.
A proof of concepts (pun intented)
Before gathering recipe data and actually uploading the data to Rubrix. I will first show you the capabilities of concise-concepts.
import spacyfrom spacy import displacyimport concise_conceptsdata = { "fruit": ["apple", "pear", "orange"], "vegetable": ["broccoli", "spinach", "tomato", "garlic", "onion", "beans"], "meat": ["beef", "pork", "fish", "lamb", "bacon", "ham", "meatball"], "dairy": ["milk", "butter", "eggs", "cheese", "cheddar", "yoghurt", "egg"], "herbs": ["rosemary", "salt", "sage", "basil", "cilantro"], "carbs": ["bread", "rice", "toast", "tortilla", "noodles", "bagel", "croissant"],}text = """ Heat the oil in a large pan and add the Onion, celery and carrots. Then, cook over a medium–low heat for 10 minutes, or until softened. Add the courgette, garlic, red peppers and oregano and cook for 2–3 minutes. Later, add some oranges and chickens. """nlp = spacy.load("en_core_web_lg", disable=["ner"])nlp.add_pipe("concise_concepts", config={"data": data, "ent_score": True})doc = nlp(text)options = { "colors": { "fruit": "darkorange", "vegetable": "limegreen", "meat": "salmon", "dairy": "lightblue", "herbs": "darkgreen", "carbs": "lightbrown", }, "ents": ["fruit", "vegetable", "meat", "dairy", "herbs", "carbs"],}ents = doc.entsfor ent in ents: new_label = f"{ent.label_} ({float(ent._.ent_score):.0%})" options["colors"][new_label] = options["colors"].get(ent.label_.lower(), None) options["ents"].append(new_label) ent.label_ = new_labeldoc.ents = entsdisplacy.render(doc, style="ent", options=options)
Gathering data
Dor gathering the data, I will use the feedparser library, which can load and parse arbitrary RSS feeds. I found some interesting RSS feeds via a quick Google search on "recipe data rss". For this post, I picked the feeds in FeedSpot. Note that I am also cleaning up some HTML-related formatting with BeautifulSoup.
import feedparserfrom bs4 import BeautifulSoup as bsrss_feeds = [ "https://thestayathomechef.com/feed", "https://101cookbooks.com/feed", "https://spendwithpennies.com/feed", "https://barefeetinthekitchen.com/feed", "https://thesouthernladycooks.com/feed", "https://ohsweetbasil.com/feed", "https://panlasangpinoy.com/feed", "https://damndelicious.net/feed", "https://leitesculinaria.com/feed", "https://inspiredtaste.com/feed",]summaries = []for source in rss_feeds: result = feedparser.parse(source) for entry in result.get("entries", []): summaries.append(entry.get("summary"))summaries = [bs(text).get_text().replace(r"\w+", "") for text in summaries]summaries[7]'Roasted Leg of Lamb is flavored with zippy lemon juice, fresh garlic, rosemary, and is topped with a sauce made from its own pan drippings and herbs. This is the best way to enjoy roast lamb!\nThe post Roasted Leg of Lamb appeared first on thestayathomechef.com.'
doc = nlp(summaries[7])ents = doc.entsfor ent in ents: new_label = f"{ent.label_} ({float(ent._.ent_score):.0%})" options["colors"][new_label] = options["colors"].get(ent.label_.lower(), None) options["ents"].append(new_label) ent.label_ = new_labeldoc.ents = entsdisplacy.render(doc, style="ent", options=options)
Calling upon Rubrix
We've gathered and cleaned our data and showed that it also works on new data. Now let's create a Rubrix dataset to explore, search, and even annotate/correct some of the few-shot predictions. Since I am running on my local environment, I decided to use the docker-compose method. In short, this launches an ElasticSearch instance to store our data, and the Rubrix server, which also comes with a nice webapp under http://localhost:6900/).
For our usecase, we are doing entity classification, which falls under the Token Classification category. Nice! There even is a tutorial specifically for spaCy.
Let's use our few-shot NER pipeline to predict over the dataset and log the predictions in Rubrix:
import rubrix as rbimport spacy# Creating spaCy docdocs = nlp.pipe(summaries)records = []for doc in docs: # Creating the prediction entity as a list of tuples (entity, start_char, end_char) prediction = [(ent.label_, ent.start_char, ent.end_char, ent._.ent_score) for ent in doc.ents] # Building TokenClassificationRecord record = rb.TokenClassificationRecord( text=doc.text, tokens=[token.text for token in doc], prediction=prediction, prediction_agent="concise-concepts-cooking", ) records.append(record)# Logging into Rubrixrb.log(records=records, name="concise-concepts")We can now go to http://localhost:6900/, explore the results and start with a base annotation for most labels. Even though the predicitons are not perfect, it surely beats starting from scratch.
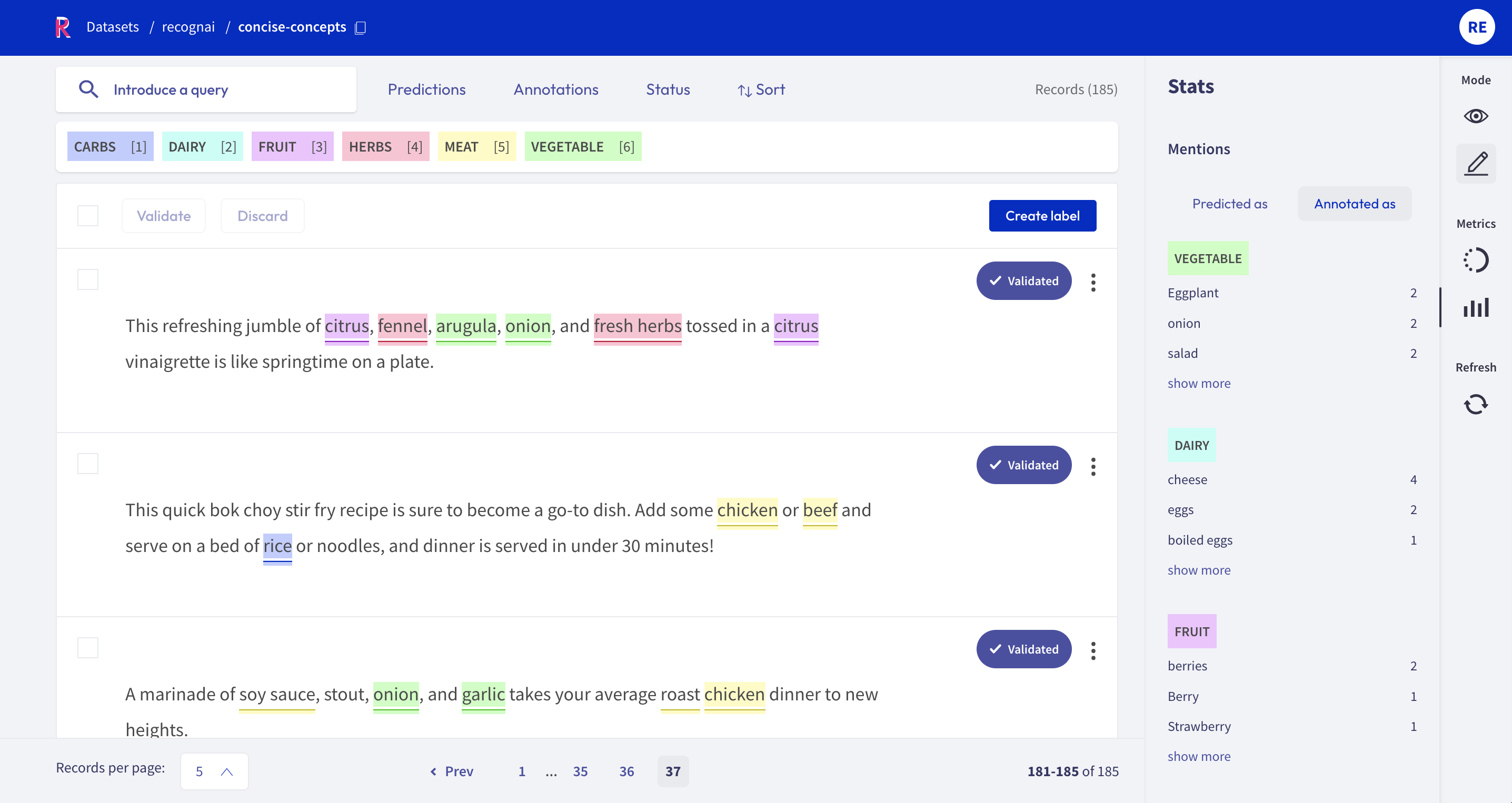
Now let's take a look at some statistics using Rubrix's Metrics module. These metrics can help us refining the definition and examples of entities given to concise-concepts. For example, the entity label metric can help us an overview of the number of occurences for each entity in concise-concepts.
from rubrix.metrics.token_classification import entity_labelsentity_labels("concise-concepts").visualize()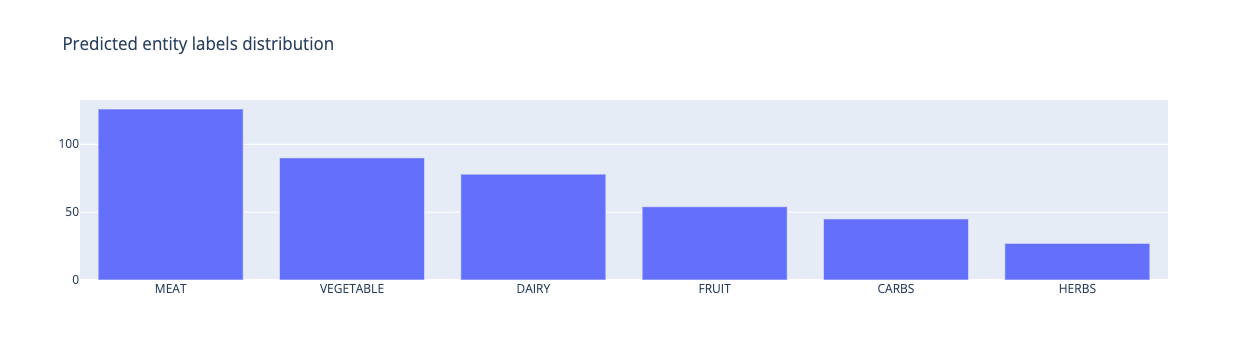
From the above, we see that the MEAT concept is being recognized more often than other concepts even though most meals only contain a single type of meat and multiple vegetables. This indicates that this concept might be a bit trigger happy. After some investigation, it shows that both "roast" and "sauce" are the culprits, since they are being recognized as MEAT.
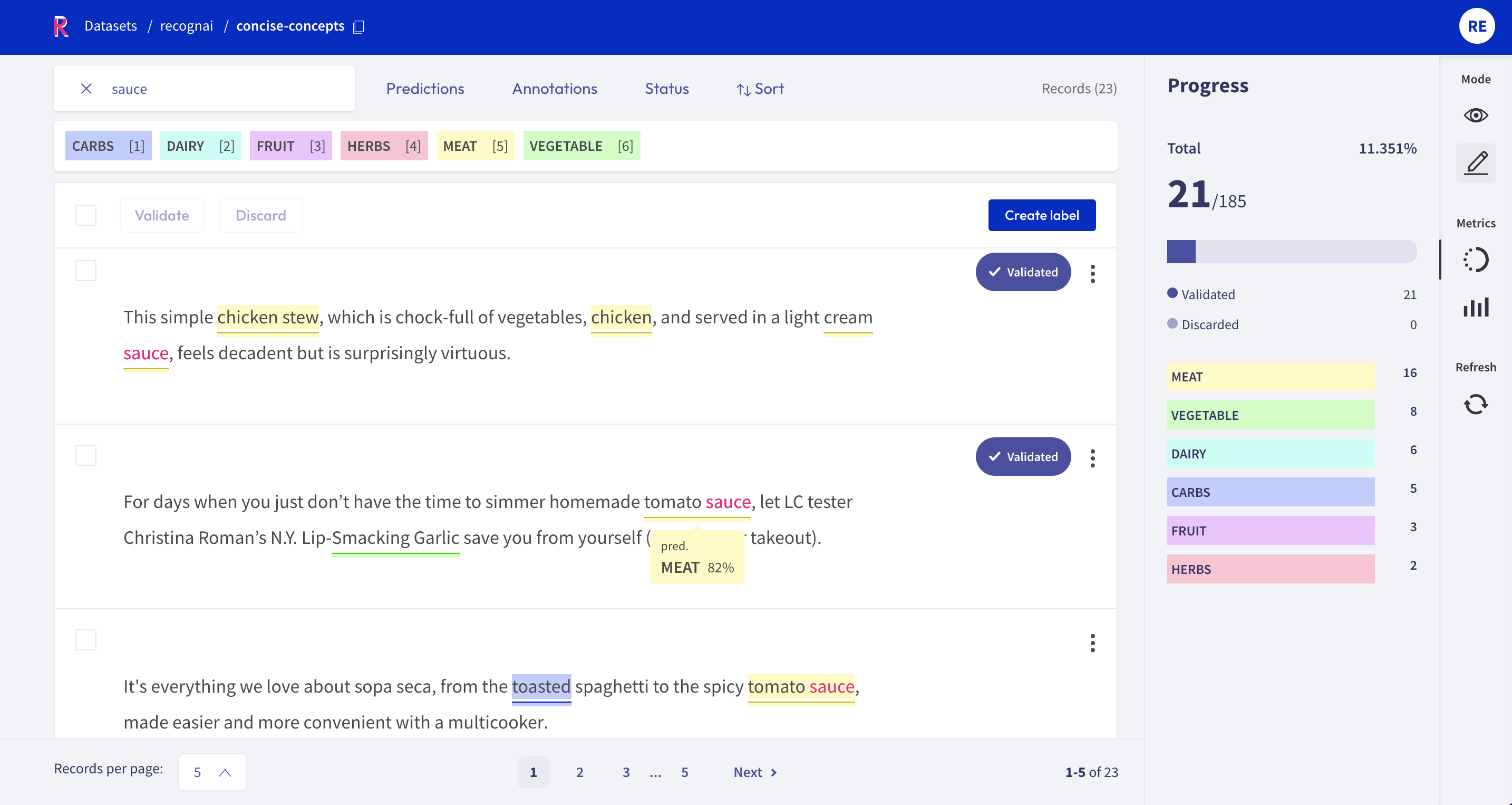
After annotating and validating some data, we are able to assess the value of our few-shot model based on some scoring metrics. We can use this to asses potential fine-tuning of our input data or the number of words to expand over, within concise-concepts.
from rubrix.metrics.token_classification import f1f1("concise-concepts").visualize()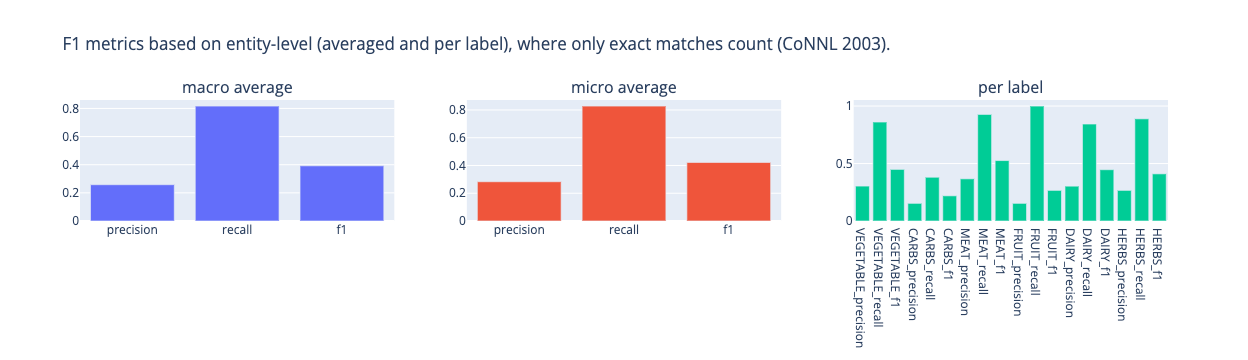
Looking at these results, we can see that the predicitons for fruits are very good, having used only 3 examples. The other labels, perform worse, which indicates that we might benefit from fine-tuning these concepts. For MEAT, we could potentially split the concept in MEAT and FISH. Similarly, the poorly performing CARBS could be split up in BREAD and GRAINS. And, we could potentially split HERBS in HERBS, CONDIMENTS and SPICES.
Summary
There are many more things we could do like fine-tuning the few-shot training data, annotate data, or train a model. However, I think I've made my point so it is time for a short recap.
We have introduced few-shot-learning and Named Entity Recognition (NER). We have also shown how a simple package like concise-concepts can be used for easy data labelling and entity scoring for any language out there, and how to store and interpret these predictions with Rubrix. Lastly, I have shown how you can completely over-engineer your hobby as a nerdy professional home cooking!
Don't forget, life is too short to eat bad food!


