We are excited to present suggestions in Argilla using Hugging Face Inference Endpoints! Starting from Argilla v1.13.0, anyone can add suggestions to Feedback Dataset records with just a few lines of code. This reduces the time to produce high-quality datasets by turning the annotation task into a quick validation and correction process.
Hugging Face's Inference Endpoints make serving any ML model on the Hub easier than ever. You just need to select the model to serve, your preferred cloud provider and region, and the instance type to be used. In a matter of minutes, you can have an up-and-running inference endpoint.
Thanks to Argilla's integration within the available Hugging Face Spaces templates, previously posted at 🚀 Launching Argilla on Hugging Face Spaces, you can get an Argilla instance up and running in just a few clicks. This allows you to keep the whole workflow within Hugging Face's ecosystem.
In this post, we will demonstrate how to set up an Argilla instance in Hugging Face Spaces, deploy a Hugging Face Inference Endpoint for serving Llama 2 7B Chat, and integrate it within Argilla to add suggestions to Argilla datasets.
With less than 10 lines of code, you can automatically add LLM-powered suggestions to the records in your Argilla dataset using Hugging Face Inference Endpoints!
🚀 Deploy Argilla in Spaces
You can self-host Argilla using one of the many deployment options, sign-up for Argilla Cloud, or launch an Argilla instance on Hugging Face Spaces with this one-click deployment button:

🍱 Push dataset to Argilla
We will be using a subset of Alpaca, which is a dataset of 52,000 instructions and demonstrations generated by OpenAI's text-davinci-003 engine using the data generation pipeline from the Self-Instruct framework with some modifications described in Alpaca's Dataset Card.
The subset of Alpaca we’ll be using has been collected by the Hugging Face H4 team and contains 100 rows per split (train and test) with the prompt and the completion.
Based on the data we want to annotate, we define the Feedback Dataset to push to Argilla, which implies the definition of the fields of each record, the questions the user needs to answer, and lastly the annotation guidelines. Find more information at Argilla Documentation - Create a Feedback Dataset.
The last step is to loop over the rows in the Alpaca subset and add those to the Feedback Dataset to be pushed to Argilla to start the annotation process.
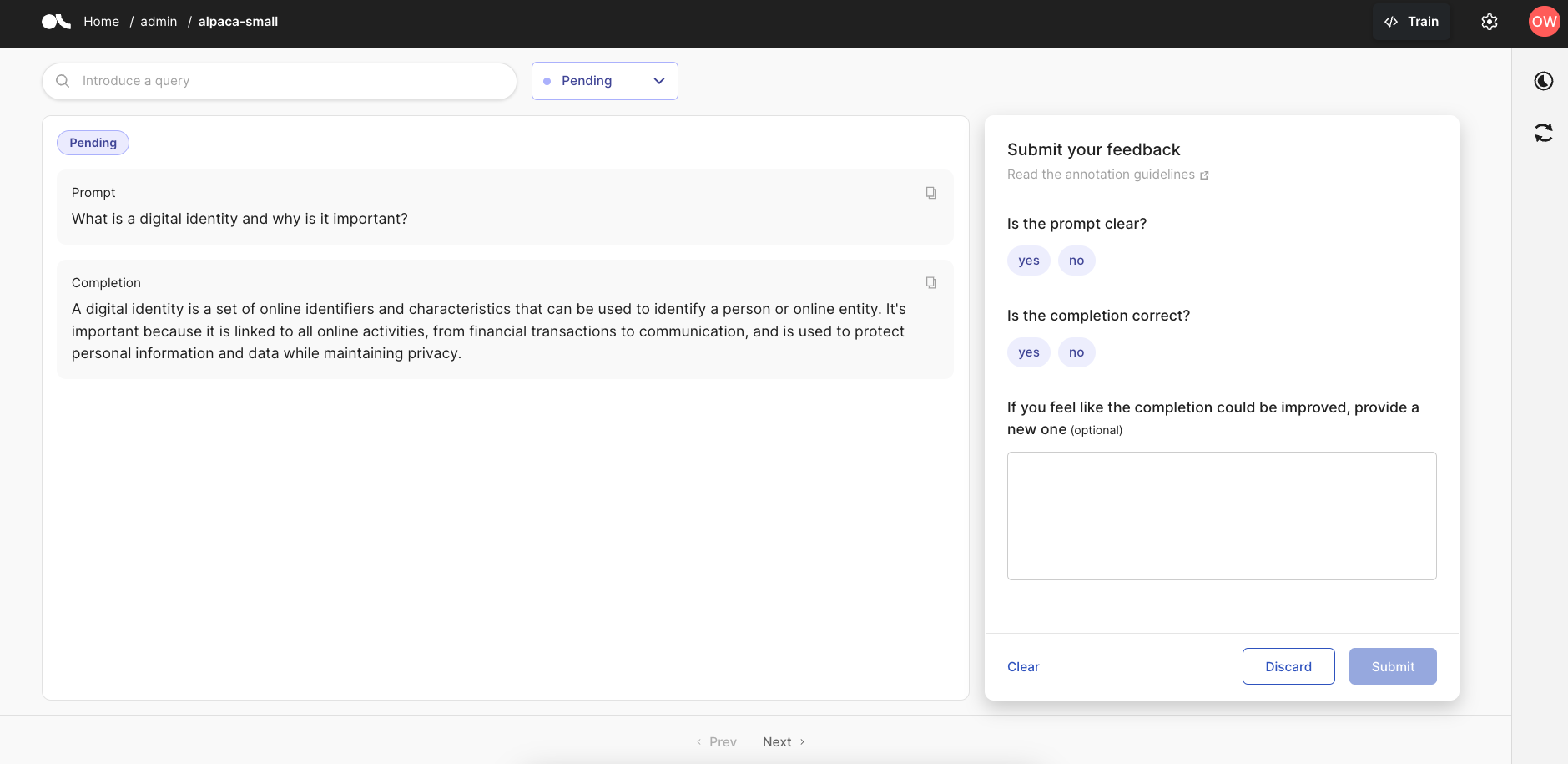
import argilla as rgfrom datasets import load_datasetrg.init(api_url="<ARGILLA_API_URL>", api_key="<ARGILLA_API_KEY>")dataset = rg.FeedbackDataset( fields=[ rg.TextField(name="prompt"), rg.TextField(name="completion"), ], questions=[ rg.LabelQuestion(name="prompt-quality", title="Is the prompt clear?", labels=["yes", "no"]), rg.LabelQuestion(name="completion-quality", title="Is the completion correct?", labels=["yes", "no"]), rg.TextQuestion( name="completion-edit", title="If you feel like the completion could be improved, provide a new one", required=False, ), ], guidelines=( "You are asked to evaluate the following prompt-completion pairs quality," " and provide a new completion if applicable." ),)alpaca_dataset = load_dataset("HuggingFaceH4/testing_alpaca_small", split="train")dataset.add_records([rg.FeedbackRecord(fields=row) for row in in alpaca_dataset])dataset.push_to_argilla(name="alpaca-small", workspace="admin")If we navigate to our Argilla instance now, we will see the following UI:
🚀 Deploy Llama 2 Inference Endpoint
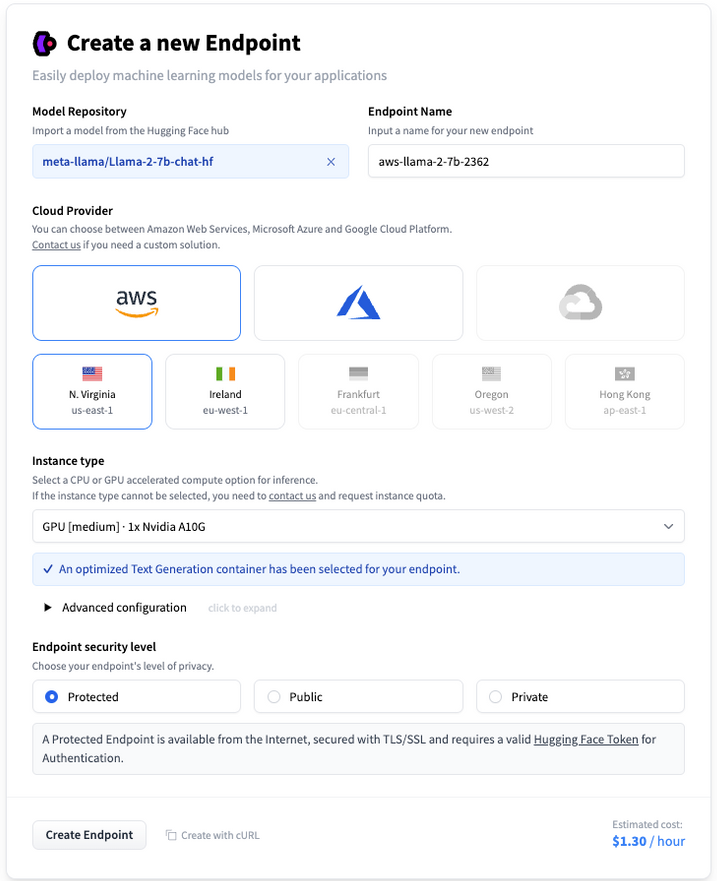
Now, we can set up the Hugging Face Inference Endpoint. This allows us to easily serve any model on a dedicated, fully managed infrastructure, while keeping costs low with their secure, compliant, and flexible production solution.
As previously mentioned, we will be using Llama 2 in its 7B parameter variant, in Hugging Face's format, fine-tuned for chat-completion. You can find this model at meta-llama/llama-2-7b-chat-hf. Additional variants are also available on the Hugging Face Hub at https://huggingface.co/meta-llama.
NOTE: In order to use Llama 2, at the time of writing this post, users will need to go to the Meta website and accept their license terms and acceptable use policy before requesting access to a Llama 2 model via the Hugging Face Hub at Meta's Llama 2 organization.
To begin, we need to ensure that the Inference Endpoint is up and running. Once we retrieve the URL, we can start sending requests to it.
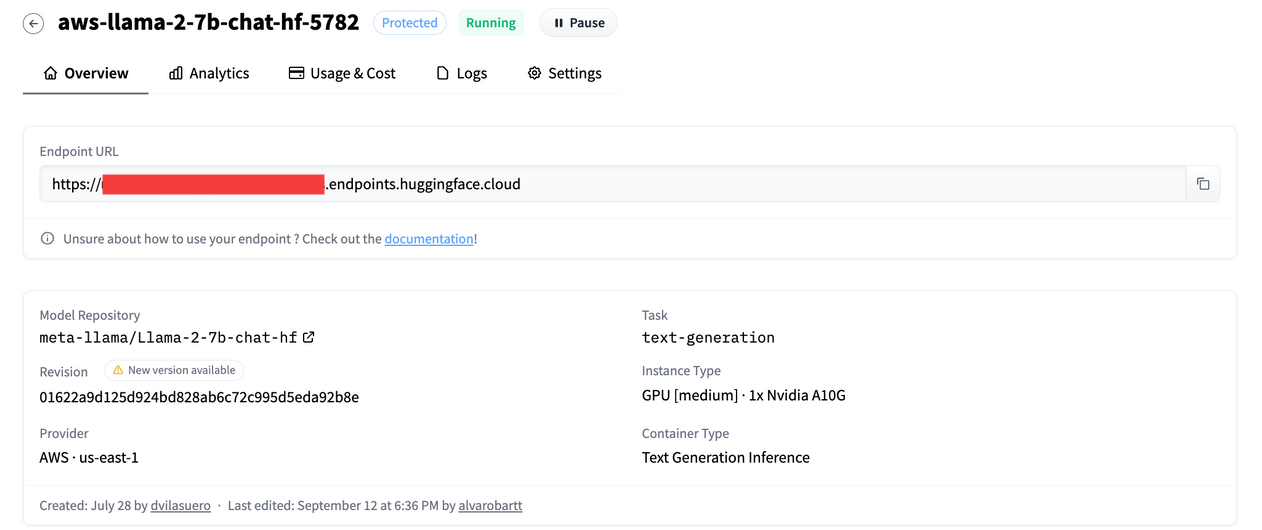
✨ Generate suggestions for Argilla
Before sending requests to the Inference Endpoint, we should know in advance which is the system prompt we need to use and how are we supposed to format our prompt. In this case, since we are using meta-llama/llama-2-7b-chat-hf, we will need to look for the prompt used to fine-tune it, and replicate the same format when sending inference requests. More information about Llama 2 at Hugging Face Blog - Llama 2 is here - get it on Hugging Face.
system_prompt = ( "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible," " while being safe. Your answers should not include any harmful, unethical, racist, sexist," " toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased" " and positive in nature.\nIf a question does not make any sense, or is not factually coherent," " explain why instead of answering something not correct. If you don't know the answer to a" " question, please don't share false information.")base_prompt = "<s>[INST] <<SYS>>\n{system_prompt}\n<</SYS>>\n\n{prompt} [/INST]"Once the prompt has been defined, we are ready to instantiate the InferenceClient from huggingface_hub to later on send requests to the Inference Endpoint via the text_generation method.
The following code snippet shows how to retrieve an existing Feedback Dataset from our Argilla instance, and how to use the InferenceClient from huggingface_hub to send requests to the deployed Inference Endpoint to add suggestions for the records in the dataset.
import argilla as rgfrom huggingface_hub import InferenceClientrg.init(api_url="<ARGILLA_SPACE_URL>", api_key="<ARGILLA_OWNER_API_KEY")dataset = rg.FeedbackDataset.from_argilla("<ARGILLA_DATASET>", workspace="<ARGILLA_WORKSPACE>")client = InferenceClient("<HF_INFERENCE_ENDPOINT_URL>", token="<HF_TOKEN>")system_prompt = ( "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible," " while being safe. Your answers should not include any harmful, unethical, racist, sexist," " toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased" " and positive in nature.\nIf a question does not make any sense, or is not factually coherent," " explain why instead of answering something not correct. If you don't know the answer to a" " question, please don't share false information.")base_prompt = "<s>[INST] <<SYS>>\n{system_prompt}\n<</SYS>>\n\n{prompt} [/INST]"def generate_response(prompt: str) -> str: prompt = base_prompt.format(system_prompt=system_prompt, prompt=prompt) response = client.text_generation( prompt, details=True, max_new_tokens=512, top_k=30, top_p=0.9, temperature=0.2, repetition_penalty=1.02, stop_sequences=["</s>"], ) return response.generated_textfor record in dataset.records: record.update( suggestions=[ { "question_name": "response", "value": generate_response(prompt=record.fields["prompt"]), "type": "model", "agent": "llama-2-7b-hf-chat", }, ], )NOTE: The pre-defined system prompt may not be suitable for the use cases so we can apply prompt engineering techniques to make it suit our specific use case.
If we jump back into our Argilla instance after generating suggestions using the Inference Endpoint, we will see the following in the UI:
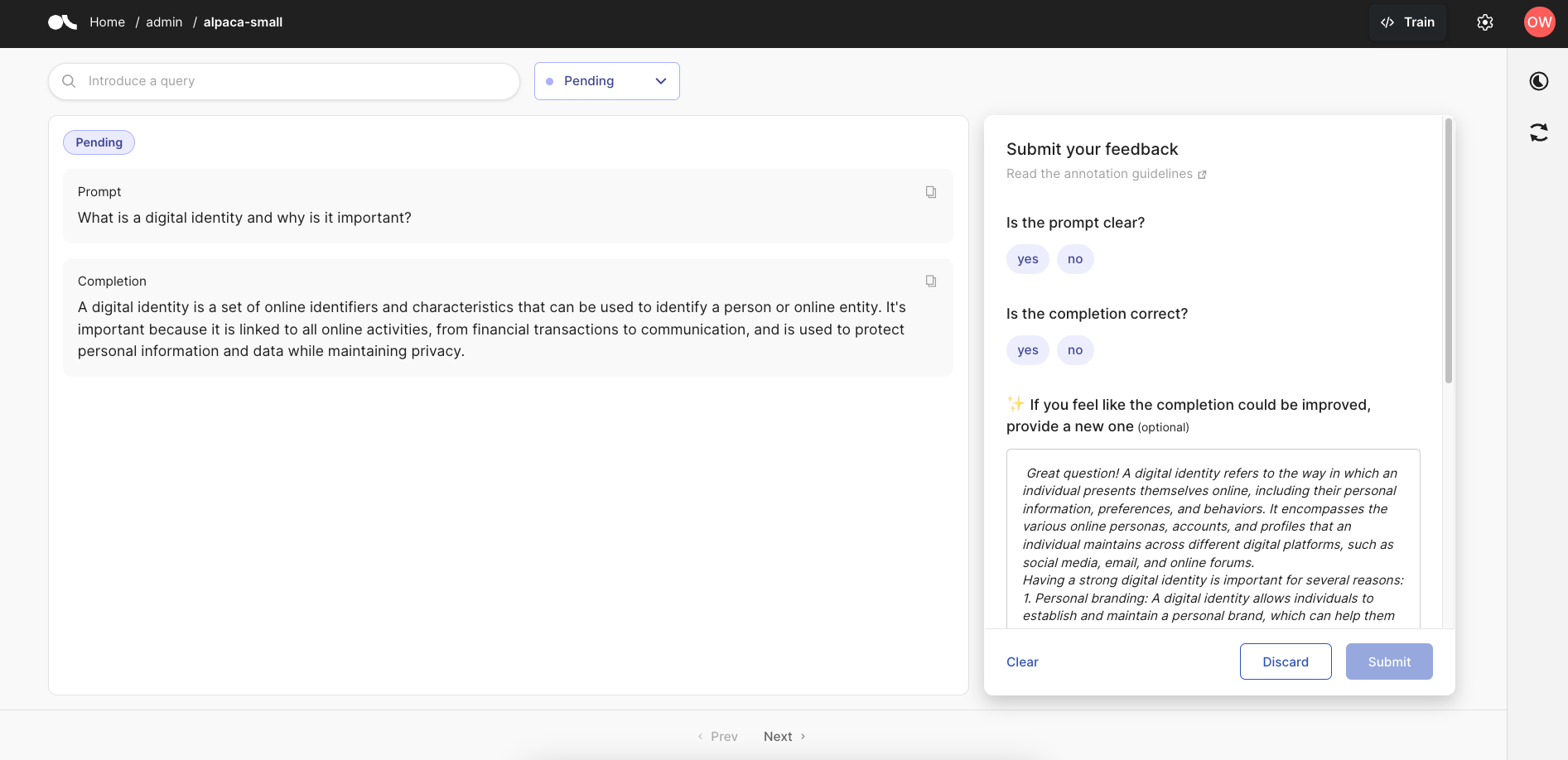
Finally, it's time for the annotators to review the records in the Argilla dataset, answer the questions, and either submit, edit, or discard suggestions as necessary.
➡️ Next steps
Using Hugging Face Inference Endpoints to inject ML-generated suggestions into Argilla has been quick and easy. Now, feel free to experiment with your favorite ML framework and generate suggestions tailored to your specific use case!
Suggestions can be generated for any question, you just need to find the model that best suits your use case and questions defined in your Feedback Dataset in Argilla.
There are plenty of use cases for suggestions, we are very excited about the role of machine feedback for LLM use cases, and we’d love to hear your ideas! We highly recommend joining our amazing Slack community to share your thoughts about this post or anything else you'd like to discuss!